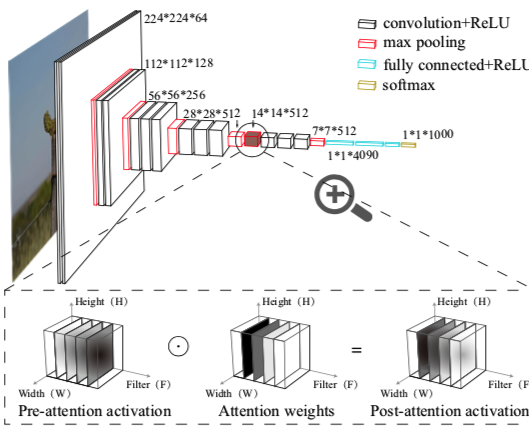
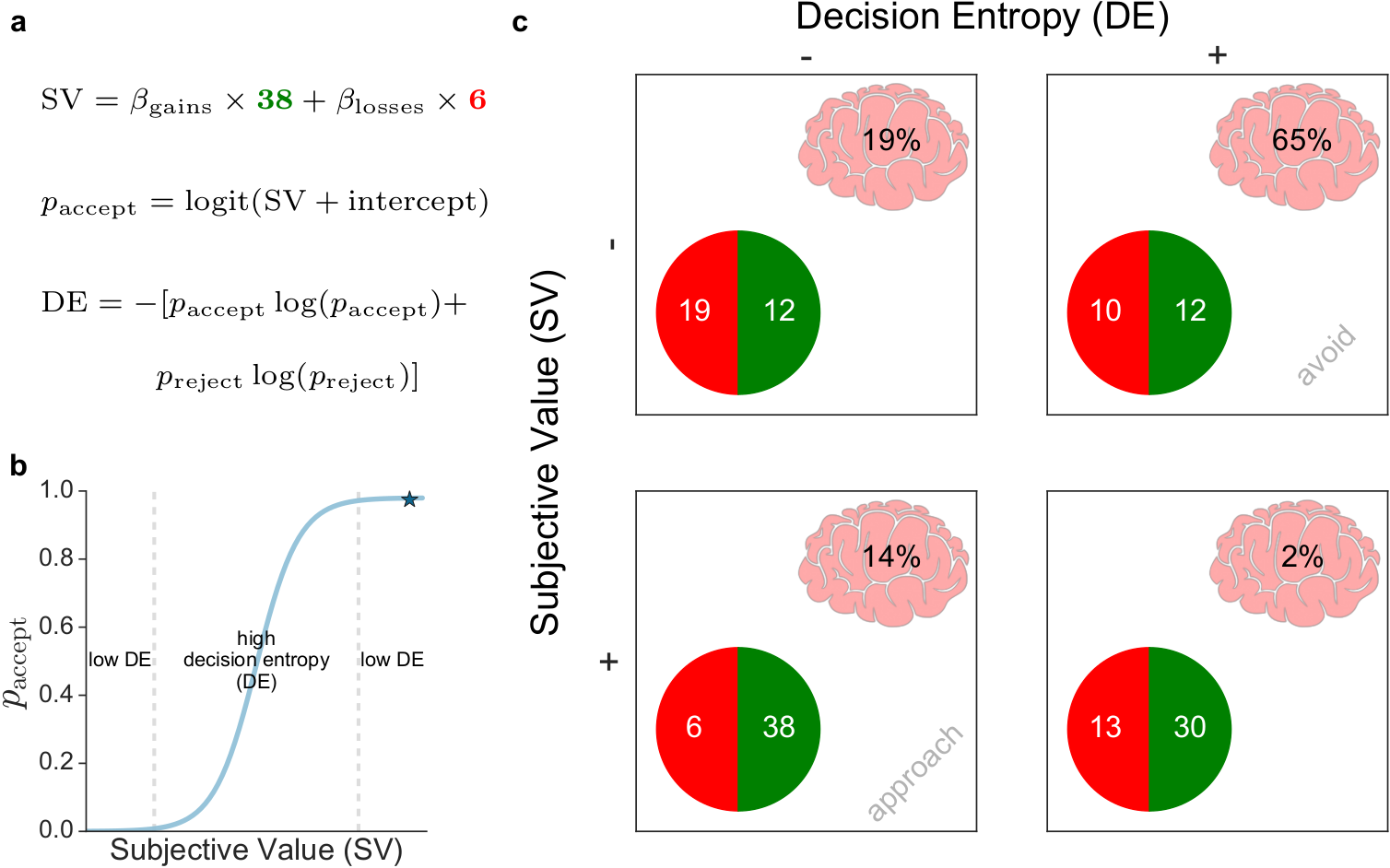
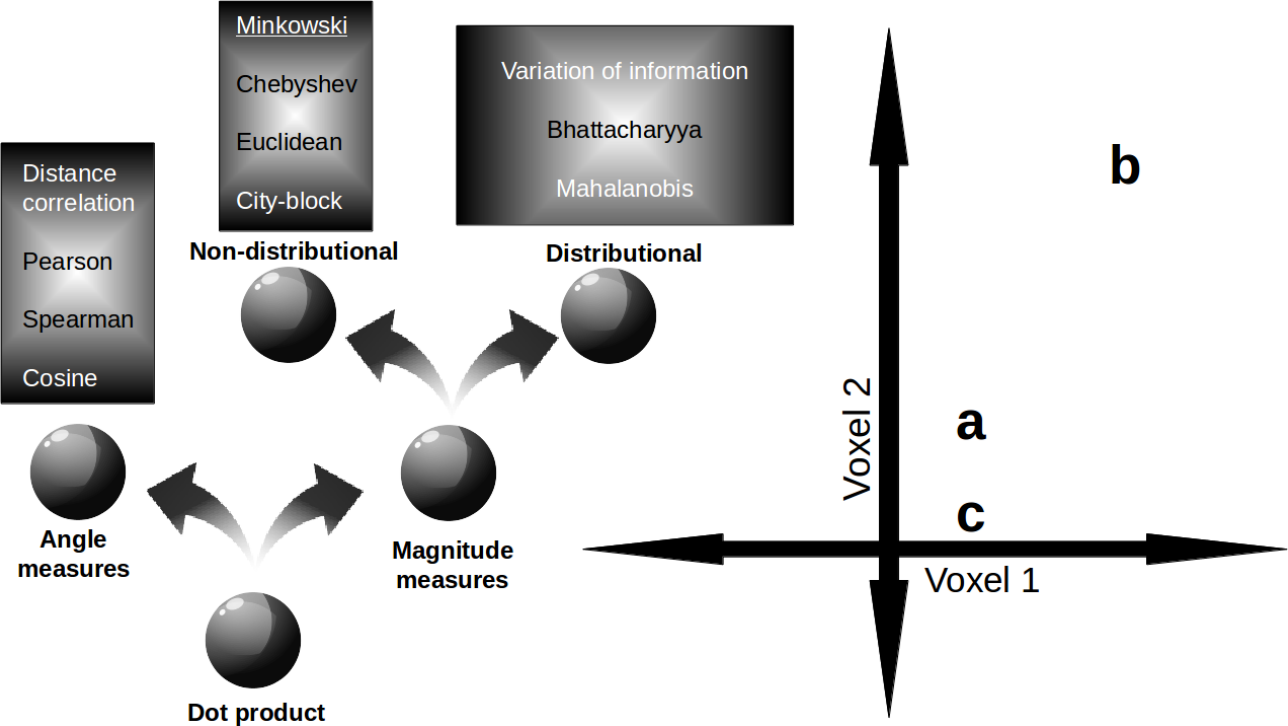
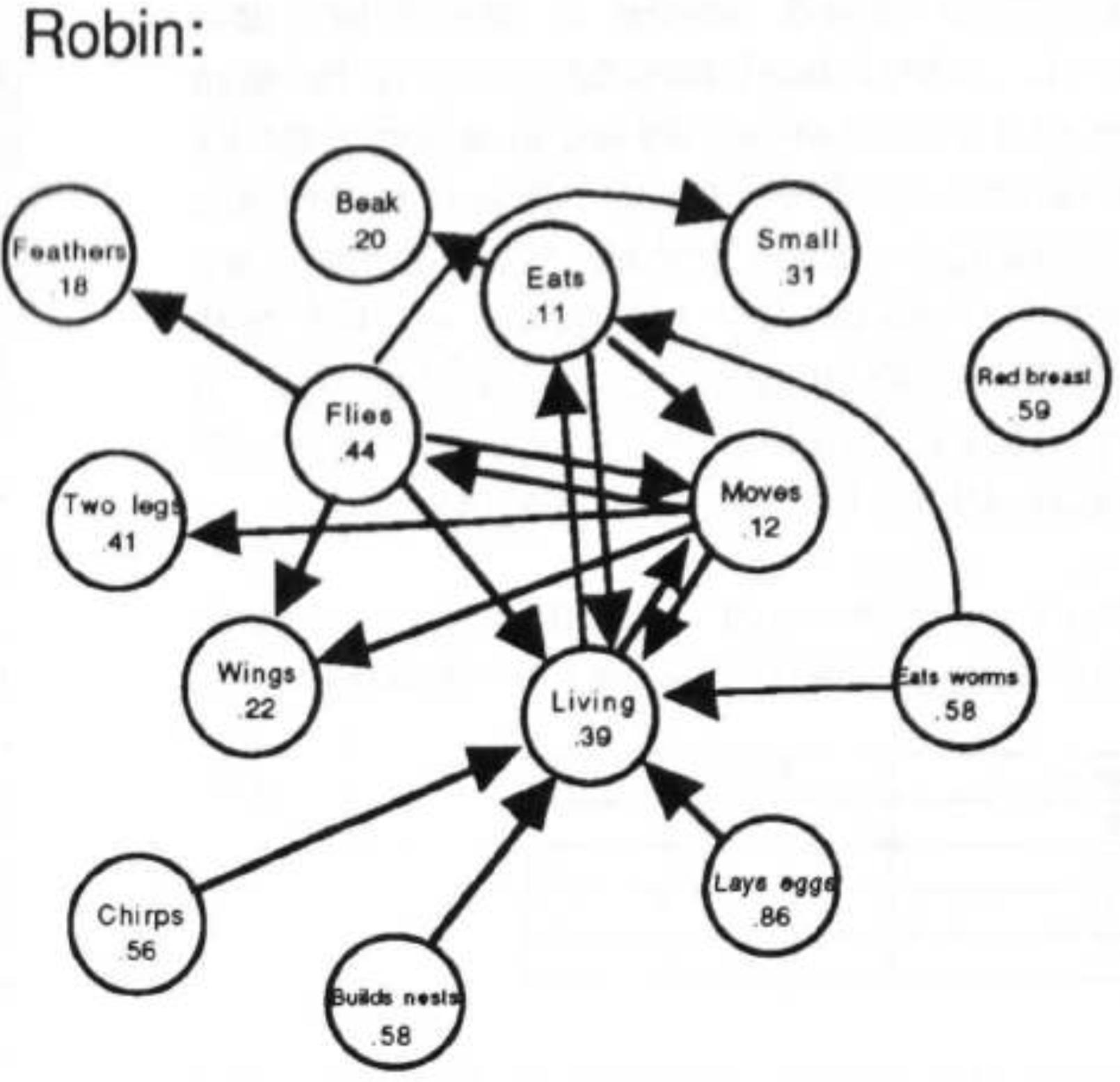
Giving LLMs too much RoPE: A limit on Sutton’s Bitter Lesson
Published on June 11, 2025,
by Xiaoliang Luo, Bradley C. Love
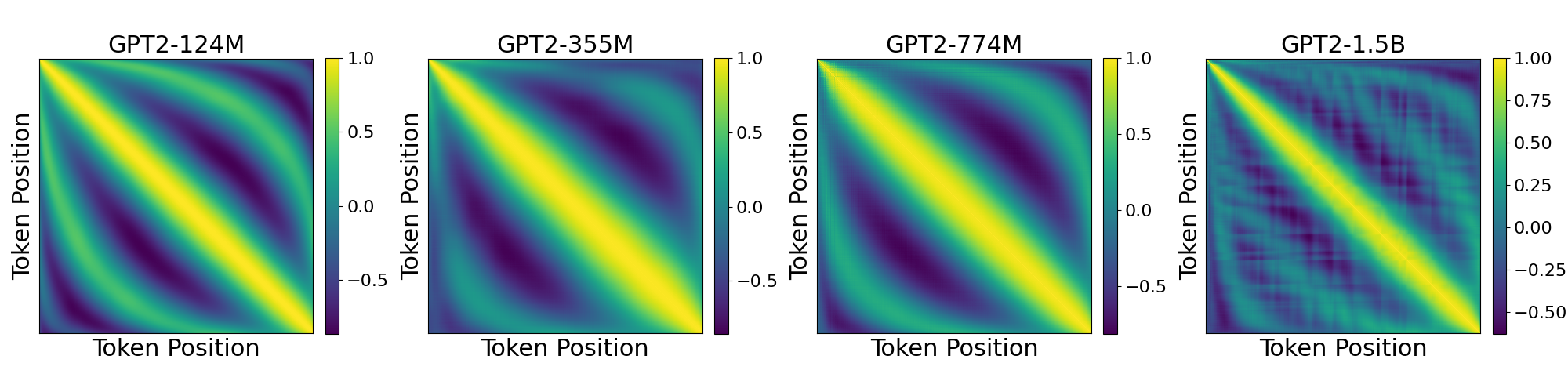
Introduction Sutton’s Bitter Lesson (Sutton, 2019) argues that machine learning breakthroughs, like AlphaGo, BERT, and large-scale vision models, rely on general, computation-driven methods that prioritize learning from data over human-crafted priors. Large language models (LLMs) based on transformer architectures exemplify this trend, scaling effectively with data and compute. Yet, positional embeddings—a key transformer component—seem to challenge this philosophy. Most embedding schemes are fixed, not learned, and embed a...
Read More